

Coups sur coups, nous avons vu apparaître les modèles génératifs sur mesure proposés par Bloomberg (BloombergGPT, et JP Morgan (DocLLM). La question s’est alors légitimement posée de savoir pourquoi ces entreprises du monde de la finance s’étaient dirigées vers la création de leurs propre modèles génératifs plutôt que d’utiliser les versions universelles disponibles (ChatGPT ou LLAMA par exemple) et si ce choix est pertinent.
In 2023, many tailor-made generative models emerged. The idea behind developing such models was simple: universal models like GPT are trained on data covering a wide range of topics (Wikipedia, web crawl, public domain books, etc.), and they produce many errors when applied to NLP tasks required in specific fields like finance. So, by training a language model more specifically with topic-oriented data, we can reduce errors and increase performance.
This is an interesting perspective – and a very costly one – as training LLMs is highly expensive: we do not speak here about fine-tuning the model but about the model trained from scratch. Two actors of US finance made the experiment. Bloomberg with BloombergGPT, and JP Morgan with DocLLM. Is this choice a valid one? Let’s investigate first the two models and then read a paper that made comparative experiments with one of those models.
The new finance-specialized models
BloombergGPT (Wu et al., 2023) is a language model with 50 billion parameters. It is trained using a mixed approach to cater to the financial industry’s diverse tasks. The dataset is made of 363 billion tokens based on Bloomberg’s extensive data sources, augmented with 345 billion tokens from general-purpose datasets. In the original paper, the model is evaluated on standard LLM benchmarks, open financial benchmarks, and Bloomberg-internal benchmarks (see the announcement here). We will see later that while the BloombergGPT team claims that the model significantly outperforms existing models in financial tasks and performs on par or even better in some general NLP benchmarks it is not so simple. BloombergGPT when launched, was tested on specialized LLMs (GPT-NeoX, OPT, BLOOM, and PALM) but not on universal models like GPT. We go deeper on this later.
DocLLM from JP Morgan is less ambitious or more focused on document analysis-related tasks: information extraction, natural language inference, visual question-answering, and document classification (while BloombergGPT is intended to work also with question-answering tasks). DocLLM is a lightweight extension to traditional large language models dedicated to reasoning over visual documents, considering both textual semantics and spatial layout. The model differs from existing multimodal LLMs by avoiding expensive image encoders and focusing exclusively on bounding box information to incorporate the spatial layout structure. The pre-trained model is fine-tuned using a large-scale instruction dataset, covering four core document intelligence tasks. The authors claim that their solution outperforms state-of-the-art LLMs on 14 out of 16 datasets across all tasks, and generalizes well to 4 out of 5 previously unseen datasets.
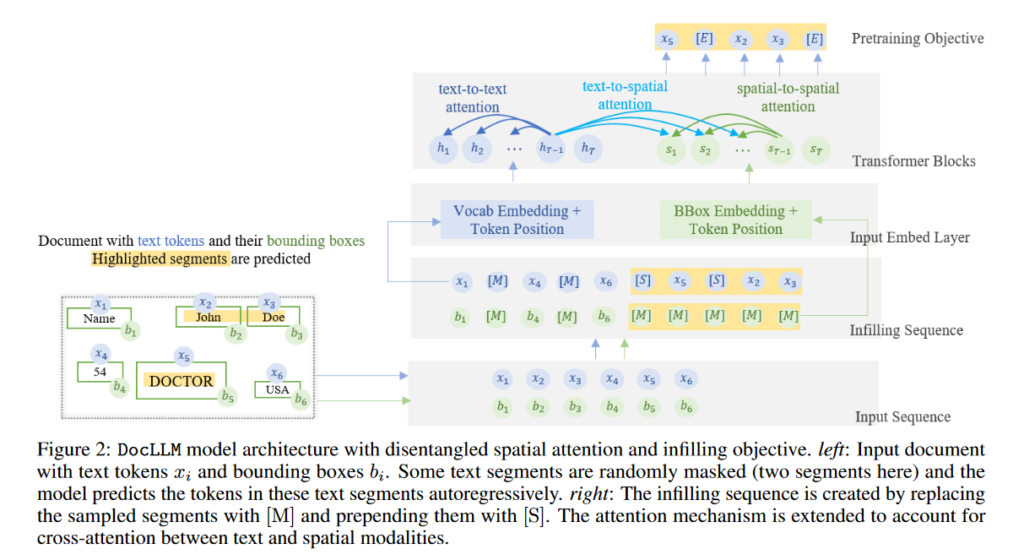
As we can see, the objectives of those two models are very different. One intends to outperform ChatGPT or LLAMA (and any universal models) on financial NLP tasks, the other is a specialized tool to question document content. A common point of those two models: they are not public and are intended to be used internally by their organization. As a consequence, it is impossible to verify the test measures provided by Bloomberg and JP Morgan or make new experiments. However, it is still possible to compare the performances of BloombergGPT evaluated with standard public metrics. That’s the objective of the paper we will detail now.
| To write this post we used / pour écrire cet article, nous avons consulté: |
| Li, Xianzhi, Samuel Chan, Xiaodan Zhu, Yulong Pei, Zhiqiang Ma, Xiaomo Liu, and Sameena Shah. “Are ChatGPT and GPT-4 General-Purpose Solvers for Financial Text Analytics? A Study on Several Typical Tasks.” In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: Industry Track, edited by Mingxuan Wang and Imed Zitouni, 408–22. Singapore: Association for Computational Linguistics, 2023. https://doi.org/10.18653/v1/2023.emnlp-industry.39. Wang, Dongsheng, Natraj Raman, Mathieu Sibue, Zhiqiang Ma, Petr Babkin, Simerjot Kaur, Yulong Pei, Armineh Nourbakhsh, and Xiaomo Liu. “DocLLM: A Layout-Aware Generative Language Model for Multimodal Document Understanding.” arXiv, December 31, 2023. https://doi.org/10.48550/arXiv.2401.00908. Wu, Shijie, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg, and Gideon Mann. “BloombergGPT: A Large Language Model for Finance.” arXiv, December 21, 2023. https://doi.org/10.48550/arXiv.2303.17564. |
A first general study of generic generative models applied to finance
In the EMNLP paper Are ChatGPT and GPT-4 General-Purpose Solvers for Financial Text Analytics? A study on Several Typical Tasks (published in December 2023), the authors conduct numerous experiments to try to give answers to the following questions:
The most recent large language models (LLMs) such as ChatGPT and GPT-4 have shown exceptional capabilities of generalist models, achieving state-of-the-art performance on a wide range of NLP tasks with little or no adaptation. How effective are such models in the financial domain? Understanding this basic question would have a significant impact on many downstream financial analytical tasks.
This is precisely the question we would like to answer about the specialized LLMs: is it worth it for an organization to invest the money required to build and train such a model? The potential of generative AI in finance is huge, but can only be delivered if the applications are viable. Many in the finance industry who have tried yet to apply generative AI for summarisation, decision help, document processing, question answering, or information retrieval have faced some headwinds in the form of unstable applications (you can’t maintain the performance of a given task), very low application performances (sometimes the tasks are properly handled but for on only 20% of the requests, the rest is ignored or wrong) and high error rates (hallucinations notably). Performance is key in a financial context: in a highly regulated environment, giving wrong advice, erroneous answers, or bad transcription of a document to customers or employees can have unacceptable (and costly) consequences.
What is interesting in this EMNLP paper is that the standard experiments conducted compare GPT and ChatGPT (including version 4) with BloombergGPT on five NLP tasks (summarized in the table below). Sentiment analysis, classification, named entity recognition (NER), question answering, and relation extraction. A set of historical NLP tasks (investigated by labs for more than 30 years now) that represents a big chunk of finance industry NLP needs. And the results are… interesting!
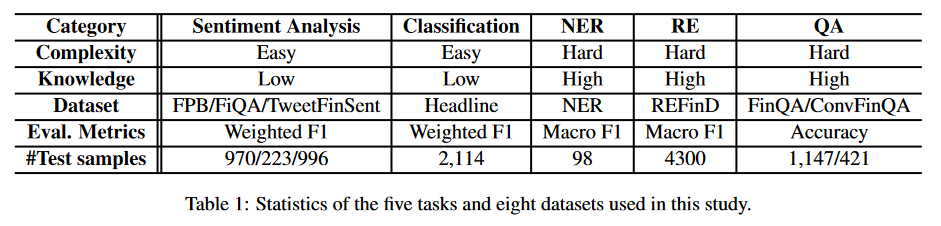
The test corpora used are classic of the domain. For sentiment analysis, Financial Phrase Bank, a typical three-scale (positive, negative, and neutral) sentiment classification task curated from financial news by 5-8 annotators (Malo et al., 2013), FiQA Sentiment Analysis, a dataset used to extend the task complexity to detect aspect-based sentiments from news and microblog in the financial domain, and TweetFinSent. Pei et al. (2022) ad dataset based on Twitter to capture retail investors’ moods regarding a specific stock ticker.
For headline classification, the authors use the news headlines classification dataset (Sinha and Khandait, 2020) from the FLUE benchmark (Shah et al., 2022). This classification task targets to classify commodity news headlines into one of the six categories like “Price Up” and “Price Down”. We could challenge this choice as the classification task in the finance industry is not only related to prices from a headline but can be much more diverse than that.
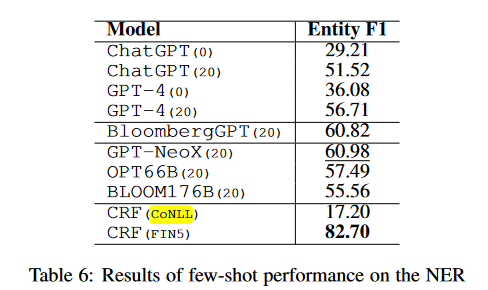
The NER task is conducted with NER FIN3 datasets, created by Salinas Alvarado et al. (2015) using financial agreements from SEC and containing four named entity types: PER (person), LOC (location), ORG (organizations), and MISC. Following the setting used in BloombergGPT, the authors remove all entities with the MISC label due to its ambiguity. Again this is a very restrictive NER test set that does not necessarily comply with finance industry needs: document information extraction in the finance and insurance industry for example involves events, product names, procedures names.
On relation extraction, the authors use the REFinD data set. This specialized financial relation extraction dataset is constructed from raw text sourced from various 10-X reports (including but not limited to 10-K and 10-Q) of publicly traded companies. These reports were obtained from the website of the U.S. Securities and Exchange Commission (SEC).
So the test sets chosen are not always the most recent, but they have one crucial advantage: they allow us to compare the real performances of universal models like ChatGPT and specialized models like Bloomberg by re-using the experiments results already published by Bloomberg. In other words, the author found a (nice) way to validate the real usefulness of BloombergGPT without having access to it. And the results are astonishing!
Experiments and results
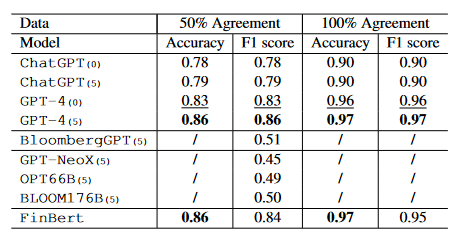
On the sentiment analysis task, GPT 4 strongly outperforms BloombergGPT. Finbert (a BERT like LLM fine-tuned for finance) also. With a gap of more than 30 points in the F1 Score, there is no advantage to using BloombergGPT on opinion mining evaluation on the Financial PhraseBank dataset.
The results of the FiQA sentiment analysis are better but still, BloombergGPT underperforms GPT 4 (by over 10 points on the weighted F1 score).
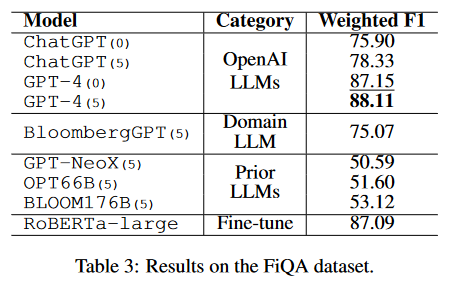
On the headline classification task BloombergGPT underperforms ChatGPT 4 by 2 points using the F1 score, but, BERT alone overperforms both of them by more than 10 points! This is fascinating as BERT is now an old language model (published in 2018).
On NER recognition – a crucial task to automate some complex document digitalization tasks in multiple industries ( NER is used for example to recognize the name of a person or an address from a scanned document, and feed a database with it), the results are surprising. The best F1 scores on this task are still those defined by the state of the art of the 2010s, using CRF classifiers! CRF specially trained on the FIN5 data overperform GPT-4 by 26 points, and BloombergGPT by 22 points! There is here a legitimate question for a practitioner on the validity of LLMs usage for the NER tasks.
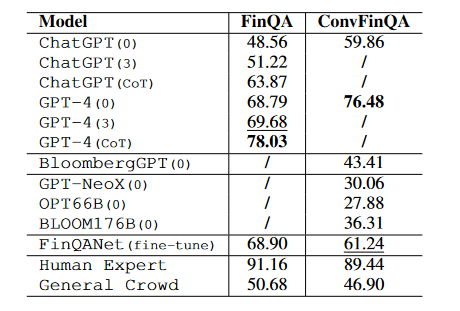
On the question-answering task, GPT4 outperformed BloombergGPT (and the other models) by more than 30 points.
A general remark: you can see in every above result table (coming from the EMNLP paper) that GPT 4 (the LLM model) overperforms ChatGPT 4 (the generative model) in all experiments. This means that using generative chat models through prompting is not necessarily the best-performing solution for NLP tasks. Something that has been demonstrated with consistency in the recent literature (see for example the systematic study conducted with the help of Royal Bank of Canada scientists below): prompting ChatGPT to extract named entities, relations, or answer questions is not performing as well as building a system the traditional way, using the sole LLM (like GPT or BERT) as a classifier.
A Systematic Study and Comprehensive Evaluation of ChatGPT on Benchmark Datasets [...] In this paper, we aim to present a thorough evaluation of ChatGPT's performance on diverse academic datasets, covering tasks like question-answering, text summarization, code generation, commonsense reasoning, mathematical problem-solving, machine translation, bias detection, and ethical considerations. Specifically, we evaluate ChatGPT across 140 tasks and analyze 255K responses it generates in these datasets. By providing a thorough assessment of ChatGPT's performance across diverse NLP tasks, this paper sets the stage for a targeted deployment of ChatGPT-like LLMs in real-world applications. Laskar, Md Tahmid Rahman, M. Saiful Bari, Mizanur Rahman, Md Amran Hossen Bhuiyan, Shafiq Joty, and Jimmy Xiangji Huang. “A Systematic Study and Comprehensive Evaluation of ChatGPT on Benchmark Datasets.” arXiv, July 5, 2023. https://doi.org/10.48550/arXiv.2305.18486.
Conclusions: a difficult and perilous path …
According to all those experiments, it is clear that on many NLP tasks, specialized models like BloombergGPT do not perform as well as universal models like GPT-4. More surprising are the experimental results when they tell us that previous state-of-the-art classifiers (like CRF) or simple language models (like BERT) still outperform generative models on NLP tasks like NER recognition or text classification. What comes from this analysis is that generative models are so new that they are highly complex to tune for specific NLP tasks and not so easy to feed with specific training data to better fit a topic like finance. An interesting finding for future deployments of this technology.