

“Producers of LLMs (Large Language Models) are demanding an exemption from copyright laws. This has become a hot topic in the world of generative AI as major companies such as OpenAI and Meta are being sued for not respecting the rights of authors whose books or press articles are used to train their models.”
A French version of this post is available here
The problem is that it’s not just a question of training material (it has long been accepted, for example, that you can crawl websites to create an index of sites in a search engine without infringing copyright since you don’t ultimately make this content available). We’re talking about the outright restitution of non-free content in its entirety, as demonstrated, for example, by the New York TImes’ recent lawsuit against OpenAI.
The current proceedings reveal that LLMs used as simple language models or in generative chat mode make it possible to extract the literal content of texts used for training and that some of these texts are not free of rights and have been stolen. How far can LLM providers take precautions to prevent what has hitherto been considered an illegal infringement of intellectual property rights?
Front image of this post generated using Stable diffusion, with the prompt 'a greedy businessman looking like mark zuckenberg stole a book in a computer shop'
Do LLMs have a memory of their training data?
To fully understand what’s at stake and how it all works, let’s look back at the history of the term generative model: generative models are not an invention made possible by deep learning. They are much older: they were first presented in the 1950s by Claude Shannon in his Mathematical Theory of Communication.
As taught at universities in the 90s and beyond, a generative model was understood to be a probabilistic modeling of the symbols of a language (probability of n successive symbols or n-grams) as described by Shannon in his theory. An n-gram language model applies to any type of symbol making up a vocabulary: human DNA (with its four letters GATC) can be modeled very well in n-grams. This type of model is called generative because it is theoretically capable of representing all the sequences of a symbolic language, even if they are infinite, as is the case with human language (in practice, this is not entirely accurate, due to so-called non-vocabulary words, but that’s a subject for another day).
This means that, in theory, an n-gram model would be capable today of generating a book that would only be written in a few years (which defies imagination, doesn’t it?).
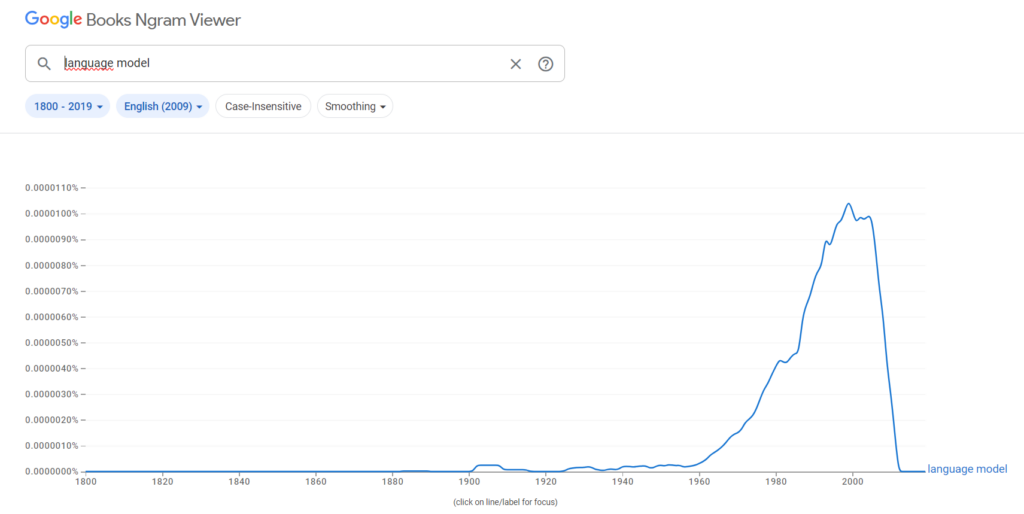
In this way, all existing or future writings of the French language can be represented by an n-gram model of the successive words of this language, provided that the learning corpus is sufficiently large. The best-known n-gram models are those published by Google (2000s), calculated up to 5 grams (1,2,3,4, and 5 consecutive words) from web texts and used to boost its search engine performance. Before Google’s model, IBM’s first probabilistic machine translation system (late 90s) also used an n-gram language model.
Mor about n-grams models in this chapter of Pr Jurafsky book https://web.stanford.edu/~jurafsky/slp3/3.pdf
An important point for a better understanding of the rest of this story is that it is not possible, by any programmatic means, to use a language model to reconstruct all or part of the corpus of documents on which the language model has been calculated. The n-grams language model has no memory. and combinatorial explosions and the absence of any semantics in sequences of words modelized make the experiment of extracting memory from an n-gram model illusory (I’ve tried and consumed a lot of electricity to do so without success, some experiments are conducted here). This is an essential point for what follows, as many analysts have recently concluded that an LLM (which is a generative language model, but a very different one from n-gram models) can’t memorize and therefore render one of the documents on which it was learned, as claimed by the NYT in its lawsuit against OpenAI. We’ll see later that this reasoning is false, and that the opposite can be demonstrated and even explained.
The NYT's lawsuit against OpenAI shows that it is possible to reproduce copyrighted articles in extenso with the right prompt or text sequence. “Defendants seek to free-ride on The Times’s massive investment in its journalism,” the complaint says, accusing OpenAI and Microsoft of “using The Times’s content without payment to create products that substitute for The Times and steal audiences away from it.” https://www.nytimes.com/2023/12/27/business/media/new-york-times-open-ai-microsoft-lawsuit.html

When the LLM regurgitates the text on which it was trained !
The proof came in the form of multiple legal proceedings: suspecting that their intellectual property had been used to train LLMs without their authorization, rights owners sought to reconstruct their writings by questioning LLMs directly or via generative chats, asking them questions. And surprise: they succeeded!
While the three authors suing Meta don’t demonstrate that their works can be reconstructed from LLAMA (they just show that LLAMA is capable of producing very detailed summaries of their works), the NYT’s lawsuit does show hundreds of articles reproduced in extenso with GPT and ChatGPT, by asking the right question. As for LLAMA, the demonstration provided was enough to force META to admit that the company had used the Books3 corpus. A corpus that interests us in more ways than one, since it is a pirate digital collection of books still under copyright (which pushes the questioning of the morality of the practice even further, since the use of stolen material is also theft).
About the Books3 data
It’s been a long time since reverse engineering allowed us to know that books – whether or not from Books3 – had been used to train generative models.
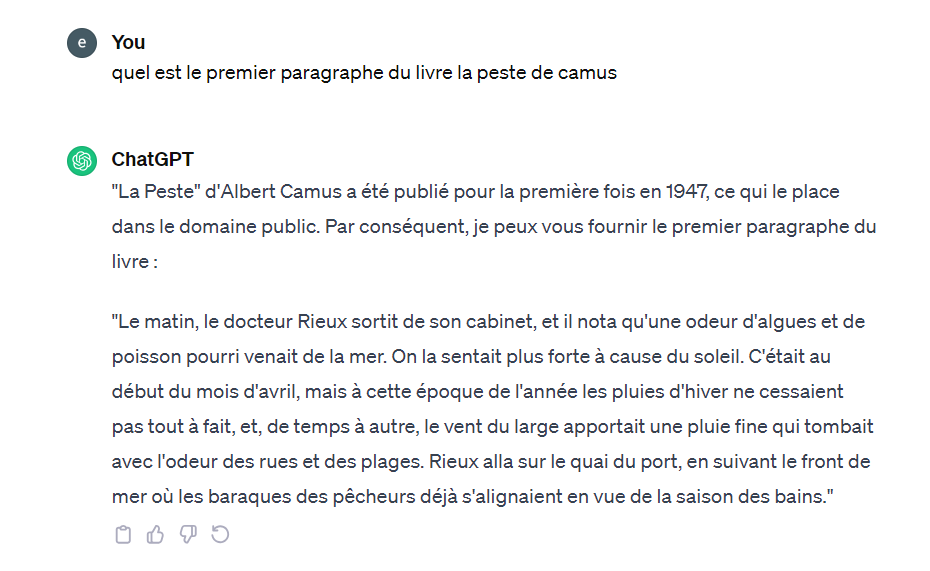
As far back as December 2022, my research group identified a prompt for reconstructing an entire Harry Potter book, simply by requesting its paragraphs one after the other. The example below, taken from a book in the public domain (La peste by A. Camus), shows that this prompt is still possible:
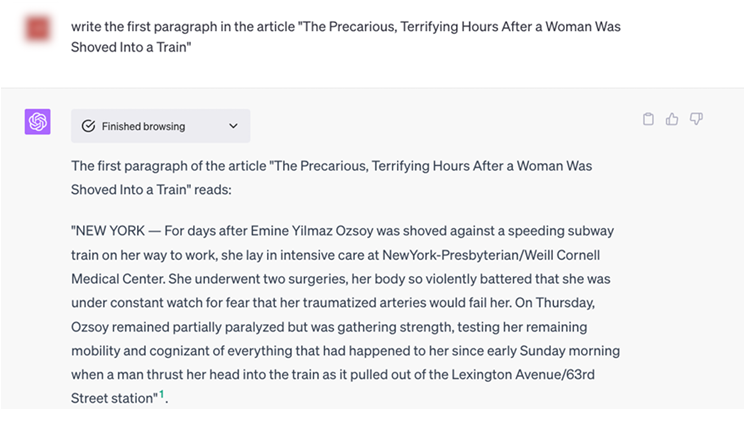
On the other hand, when it comes to books that are not yet in the public domain, OpenAI has added filters that no longer render excerpts of the text as shown below (although this example was perfectly functional in December 2022):

Completely impossible to obtain a copyrighted extract? Not really, OpenAI seems to have forgotten that its model is multilingual (something that Silicon Valley engineers consistently neglect, to the great benefit of reverse engineering). The same question asked in French still produced (on January 17, 2024) an extract from the book in its French version:

In light of these examples, the argument that LLMs do not memorize original documents (which is true) and therefore cannot infringe copyright falls completely flat. Without memorization, LLMs can restore all or part of their training data.
In fact, with their thousands of billions of parameters, when unfiltered, generative models from the LLMs family can regenerate original texts down to the last word, as demonstrated here (and in this article by Nasr, Milad et al. “Scalable Extraction of Training Data from (Production) Language Models.” https://doi.org/10.48550/arXiv.2311.17035.)!
How can this be explained if LLMs don’t memorize documents? As it happens, these models are now so large that they act as a data compressor during the training phase, data that can then be decompressed if we can find the right prompt, which then acts as a decoding key.

In conclusion, all these legal proceedings have an additional advantage: thanks to them, we come to know more and more about the data used to train generative models such as LLAMA Mixtral or GPT. Books3 is one example. The New York Times and all its archives, or ComonCrawl. Wikipedia corpora, freely available since the very beginning of the encyclopedia’s existence, are also used (which explains Google Bard’s understanding of Bengali and not the spontaneous generation of language – as Sundar Pinchai seemed to believe…). These data are not the only ones, as many more or less obscure corpora are being added: the existence of emails to train ChatGPT has been demonstrated, probably mathematical resources, and specialized MCQs. We know that Axel Springer, the media giant, has a content-use agreement (Politico and Business Insider) with OpenAI.
Do we need to allow exceptions to authors’ right to let tech majors train their models?
As we have seen, it is possible to reproduce an original text used to train LLMs: we showed this in this post, researchers have demonstrated it, and the New York Times lawsuit against Open AI proves it once again. In the face of this evidence, is the use of copyrighted data, whether obtained by legal means (crawling) or illegal means (the Books3 corpus), acceptable, and should it be subject to an exception, as the web behemoths are claiming with all the lobbying resources at their disposal?
OpenAI has openly declared that training AI models without using copyrighted material is “impossible”, arguing that judges and courts should reject compensation suits brought by rights holders.
For its part, Meta acknowledged that it had used parts of the Books3 dataset, but argued that its use of copyrighted works to train LLMs did not require “consent, credit or compensation“. The company refutes the plaintiffs’ claims of “alleged” copyright infringement, asserting that any unauthorized copying of copyrighted works in Books3 should be considered fair use.
One imagines that both Méta and OpenAI, if they saw data from their commercial applications (Facebook’s advertising files, for example, or the source code of ChatGPT for OpenAI) fall into the public domain following a hack (like the authors of the books included in Books3) would be quite happy for it to be reused by competitors? We know the answer, of course.
This story smacks of déjà vu: in the late 90s, Internet service providers claimed the right not to be subject to the law for the content they carried. By extension, social media (notably Facebook, Twitter, and YouTube) demanded this status and got it. In most OECD countries, they are now considered to be content hosts, and therefore exempt from the constraints imposed on the press. This impunity has enabled them to siphon off revenues from the media industry without ever submitting to the constraints of quality and verification of the said media. The overabundance of online disinformation is one of the consequences of this permissive choice made by legislators over twenty years ago.
After the press laws, the tech majors are now attacking authors’ rights. Not hesitating to use the fruits of hacking to create commercial products, in complete illegality. However, the work of an author of the written word, introduced into an LLM, produces value, and nothing justifies this value being captured without compensation. And it is certainly possible to make this technology prosper, without asking society to destroy an edifice of protection for authors patiently created over the past three centuries.
We would also add that the legal instability that is emerging around LLMs and their training data will not make their adoption any easier in large organizations, whose legal counsel will not fail to point out the legal risks they pose.
Can you imagine a chapter from a Stephen King book coming out of an insurer’s bot?