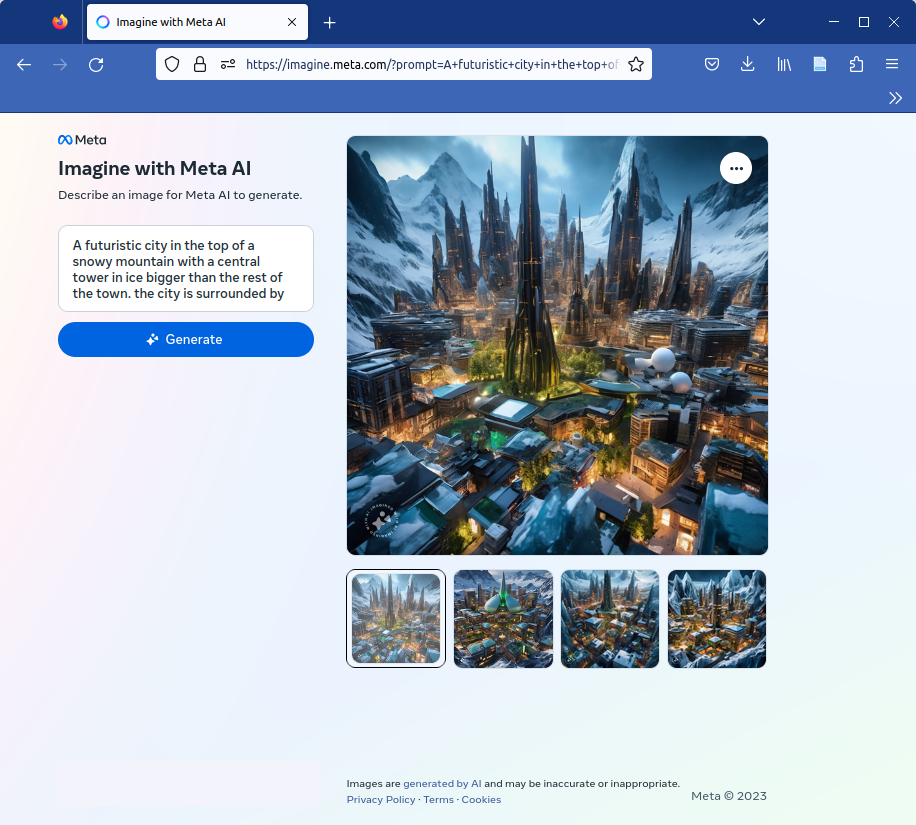
Imagine, the new image generation engine from meta
Meta released yesterday a pretty nice new image generation engine As for more demo related to generative AI recently (in my case, connecting from Canada, all generative demos from Google like Bard or Meta can not be accessed), you will have to be connected from the validated countries to have access to it . Currently, Imagine Meta is only accessible from US.
It is included in the new demo page announced by Meta : To close out the year, we’re testing more than 20 new ways generative AI can improve your experiences across Facebook, Instagram, Messenger, and WhatsApp — spanning search, social discovery, ads, business messaging and more.
In this post we only present the generative module for image, but there is many others interesting tools promoted (see the list here).
a futuristic car driven by an extraterrestrial entity
As in the illustration 2, bellow, we can see that the engine (apparently trained on Instagram pictures) do not interpret easily some complex requests (in this example the futuristic depiction is not processed). The usual difficulty for those models to depict fingers that is now completely removed from Midjourney is still present with this version of the facebook model.
2 : some futuristic dressed people in a london pub from the 18th century. In the background we see the streets of london with people
But – even if the semantic content of the sentences is not fully interpreted – the creativity and the aesthetic is impressive as we can see in the illustration 3.
3 : a modern city in the african jungle where everybody have the head of an animal
Imagine uses Emu technology, the image foundation model of Meta. It is said that Meta used 1.1 billion publicly visible Facebook and Instagram images to train the model. Previously, Meta’s version of this technology—using the same data—was only available in messaging and social networking apps such as Instagram.
Arstechnica explain to us that If you’re on Facebook or Instagram, it’s quite possible a picture of you (or that you took) helped train Emu. In a way, the old saying, “If you’re not paying for it, you are the product” has taken on a whole new meaning. Although, as of 2016, Instagram users uploaded over 95 million photos a day, so the dataset Meta used to train its AI model was a small subset of its overall photo library. Lets see if a hack comes in literature that will allow to reverse engineer Emu and its training corpora !
Meta published a research paper on Emu, available here and they give a lot of details on how they constructed and trained their system. The abstract of the paper with some information on training data and performances is bellow. Emu is based on a latent diffusion model with an emphasis on fine tuning. Approach involves a knowledge learning stage followed by a quality-tuning stage (see section 3 of the meta paper).
Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack
Abstract :
Training text-to-image models with web scale image-text pairs enables the generation of a wide range of visual concepts from text. However, these pre-trained models often face challenges when it comes to generating highly aesthetic images. This creates the need for aesthetic alignment post pre-training. In this paper, we propose quality-tuning to effectively guide a pre-trained model to exclusively generate highly visually appealing images, while maintaining generality across visual concepts. Our key insight is that supervised fine-tuning with a set of surprisingly small but extremely visually appealing images can significantly improve the generation quality. We pre-train a latent diffusion model on 1.1 billion image-text pairs and fine-tune it with only a few thousand carefully selected high-quality images. The resulting model, Emu, achieves a win rate of 82.9% compared with its pre-trained only counterpart. Compared to the state-of-the-art SDXLv1.0, Emu is preferred 68.4% and 71.3% of the time on visual appeal on the standard PartiPrompts and our Open User Input benchmark based on the real-world usage of text-to-image models. In addition, we show that quality-tuning is a generic approach that is also effective for other architectures, including pixel diffusion and masked generative transformer models.
You can experiment the tool (with the proper geographic localization) at imagine.meta.com