Les producteurs de LLM demandent à être exonérés du droit d’auteur ! C’est le nouveau sujet de l’IA générative: poursuivis de tous côté, les majors du net, OpenAI et Meta en tête, revendiquent de ne pas avoir à respecter les droits des auteurs d’ouvrages ou d’articles de presse qu’ils utilisent pour entraîner leurs modèles.
Une version anglaise de ce post est disponible ici
Le problème est qu’il ne s’agit pas uniquement d’une question de matériel d’entraînement (on a admis par exemple depuis longtemps, qu’on peut crawler des sites web pour créer un index de sites dans un engin de recherche sans violer le droit d’auteur puisqu’on ne rends pas in fine ce contenu disponible). Il s’agit ici de s’autoriser la restitution pure et simple de contenus non libres dans leur intégralité, tels que l’a démontré par exemple la récente poursuite du New York Times contre OpenAI.
Ce que révèlent les procédures en cours, c’est que les LLM utilisés comme simple modèle de langue ou en mode chat génératif ont la mémoire de tout ou partie de leurs données d’apprentissage, permettent de ressortir le contenu littéral des textes utilisés pour l’entraînement, et que certains de ces textes ne sont pas libres de droits et ont été volés. Jusqu’où va la responsabilité d’un fournisseur de LLM dans les précautions qu’il doit prendre pour empêcher que ce qui était jusqu’ici considéré comme une atteinte illégale à la propriété intellectuelle puisse se produire ?
Illustration de cet article : image générée avec Stable diffusion, en utilisant le prompt 'a greedy businessman looking like mark zuckenberg stole a book in a computer shop'
Un modèle de langue génératif peut-il recréer le texte sur lequel il a été appris ?
Pour bien comprendre les enjeux et les rouages sous-jacents, revenons un instant sur l’histoire du terme modèle génératif : les modèles génératifs ne sont pas une invention rendue possible par le deep learning. Ils sont bien plus anciens : ils ont été présentés pour la première fois dans les années 50 par Claude Shannon dans sa Théorie mathématique de la communication.
Tel qu’enseigné à l’université dans les années 90 et suivantes, on entendait par modèle génératif, une modélisation probabiliste des symboles d’un langage (probabilité de n symboles successifs ou n-grams) tel que décrite par Shannon dans sa théorie . Un modèle de langue n-gramme s’applique à tout type de symbole composant un vocabulaire : l’ADN humain (avec ses quatre lettres GATC) se modélise très bien en n-grammes. On qualifie ce type de modèle de génératif par ce qu’il est théoriquement capable de représenter la totalité des séquences d’un langage symbolique, y compris si elle est infinie, comme dans le langage humain (en pratique ce n’est pas totalement exact en raison de ce qu’on appelle les mots hors vocabulaire, mais ce sujet sera pour un autre jour) .
Ainsi, tous les écrits existants ou à venir de la langue francaise peuvent être représentés par un modèle n-grammes des mots successifs de cette langue, pour peux que le corpus d’apprentissage soit suffisamment vaste. Les modèles n-grammes les plus connus sont ceux publiés par Google (années 2000), calculés jusqu’au 5 grammes (1,2,3,4, et 5 mots consécutifs) d’après les textes du web et utilisés pour augmenter la performance de son engin de recherche. Avant le modèle de Google, le premier système probabiliste de traduction automatique conçu par IBM (fin des années 90) utilisait lui aussi un modèle de langue n-gramme.
Pour en apprendre plus sur les modèles n-grammes, lire ce chapitre de livre du Pr Jurafsky https://web.stanford.edu/~jurafsky/slp3/3.pdf
Point important pour la suite de cette étude: il est impossible par un moyen programmatique quelconque en utilisant ce modèle de langue de reconstituer tout ou partie du corpus documentaire sur lequel le modèle de langue n-grammes été calculé. Le modèle de langue n’a pas de mémoire. Les explosions combinatoires et l’absence de notion de sémantique dans une suites de mots et leur probabilité d’apparition rendent l’expérience à ce jour illusoire (j’ai essayé et consommé beaucoup d’électricité pour y parvenir, quelques expériences sont menée ici). C’est un point essentiel pour la suite car partant de ce principe, de nombreux analystes ont conclus récemment qu’il était impossible qu’un LLM (qui est un modèle de langue génératif mais très différent des modèles n-grammes) puisse mémoriser et donc restituer un des documents sur lequel il a été appris, tel que revendiqué par le New York Time (NYT) dans sa poursuite contre OpenAI. Nous verrons plus loin que ce raisonnement est faux, que le contraire peut être démontré et même expliqué.
La poursuite du NYT contre OpenAI et Microsoft montre qu'il est possible de reproduire in extenso des articles sous droits d'auteur avec le bon prompt ou la bonne séquence de texte. “Defendants seek to free-ride on The Times’s massive investment in its journalism,” the complaint says, accusing OpenAI and Microsoft of “using The Times’s content without payment to create products that substitute for The Times and steal audiences away from it.” https://www.nytimes.com/2023/12/27/business/media/new-york-times-open-ai-microsoft-lawsuit.html

Quand le LLM régurgite le texte sur lequel il a été appris !
Et la démonstration est venue de multiple procédure judiciaires : soupçonnant que leur propriété intellectuelle avait été utilisée pour entraîner des LLM sans leur autorisation, des propriétaires de droits ont cherché à reconstituer leurs écrits en interrogeant les LLM directement ou via les chats génératifs, en leur posant des questions. Et surprise : ils y sont parvenus !
Si les trois auteurs qui poursuivent Meta ne démontrent pas qu’on peut reconstituer leurs ouvrages depuis LLAMA (ils montrent juste que LLAMA est capable de produire des résumés très détaillés de leurs œuvres), on peut en revanche retrouver dans la poursuite du NYT des centaines d’articles reproduits in extenso avec GPT et ChatGPT, en lui posant la bonne question. Et pour ce qui est LLAMA, la démonstration des auteurs plaignants a suffi pour forcer Meta à admettre que l’entreprise avait utilisé le corpus Books3. Un corpus qui nous intéresse à plus d’un titre puisqu’il s’agit d’un recueil digital pirate de livres encore sous droits d’auteurs (ce qui pousse encore plus loin le questionnement sur la moralité de la pratique puisque l’utilisation d’un matériau volé est aussi du vol).
Qu'est ce que Books3 ? Books3 est un ensemble de données contenant 196 640 livres au format texte non libres de droits rédigés par des auteurs tels que Stephen King, Margaret Atwood et Zadie Smith, utilisés pour entraîner des modèles de langage. Assemblé en 2020 par Shawn Presser, défenseur de l'open source, il est hébergé par The Eye, un site Web « dédié à l'archivage et à la diffusion d'informations accessibles au public ».
Le cas de Books3
Il y a très longtemps que l’ingénierie inverse nous permet de savoir que des livres – issus ou non de Books3 – ont été utilisés pour entraîner les modèles génératifs.
Dès le mois de décembre 2022, nous avions identifié dans mon groupe de recherche un prompt permettant de reconstituer un livre entier de Harry Potter, simplement en demandant ses paragraphes les uns après les autres. On peut voir dans l’exemple ci dessous, pris sur un livre dans le domaine public (La peste de A. Camus) que cette possibilité de prompt demeure :
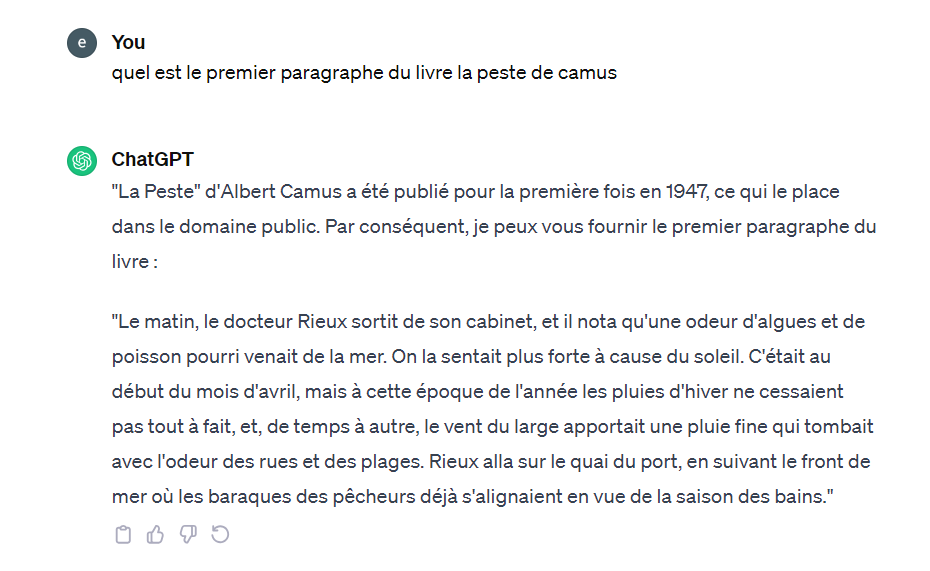
En revanche, dès qu’il s’agit d’un livre qui n’est pas encore dans le domaine public, OpenAI a manifestement ajouté des filtres qui ne permettent plus de restituer les extraits du texte comme on le voit si dessous (alors que cette exemple était parfaitement fonctionnel en décembre 2022) :

Complètement impossible d’obtenir un extrait sous copyright ? Pas vraiment, OpenAI semble avoir oublié que son modèle était multilingue (quelque chose que les ingénieurs de la Silicon Valley négligent avec constance pour le plus grand profit de l’ingénierie inverse). La même question posée en français produit toujours le 17 janvier 2024) un extrait du livre dans sa version française :

Ajoutons à la lumière de ces exemples que l’argument de ceux qui voudraient que les LLM ne mémorisent pas les documents originaux (ce qui est vrai) et donc qu’ils ne sauraient enfreindre le droit d’auteur tombe complètement à l’eau. Sans mémorisation, les LLM sont bel et bien en mesure de restituer tout ou partie de leurs données d’apprentissage.
En réalité avec leurs milliers de milliards de paramètres, lorsqu’ils ne sont pas filtrés, les modèles génératifs de la famille des LLM permettent bien de régénérer au mot près des textes originaux comme la démonstration en est faite ici (et par cet article de Nasr, Milad et al. “Scalable Extraction of Training Data from (Production) Language Models.” https://doi.org/10.48550/arXiv.2311.17035.) !
Comment l’expliquer si les LLM ne mémorisent pas les documents ? En l’occurrence, ces modèles sont aujourd’hui si grands qu’ils agissent apparemment comme un compresseur de données lors de la phase l’entraînement, données qu’il est ensuite possible de décompresser pour peux que nous trouvions le bon prompt (ou la bonne séquence) qui agit alors comme une clé de décodage. On ne connaît pas encore exactement les mécanismes de la mémorisation des données d’entraînement par les LLM, mais il ne fait plus aucun doute aujourd’hui que cette capacité existe pour un pourcentage non négligeable de ces données (des expériences commencent à apparaître).

Mentionnons pour conclure sur ce point que toutes les procédures judiciaires que nous venons de mentionner ont un avantage supplémentaire: grâce à elles, on finit par en savoir de plus en plus sur les données utilisées pour entraîner les modèles génératifs tels que LLAMA Mixtral ou GPT. Books3 est un exemple. le New York Times et toutes ses archives, ou encore ComonCrawl en sont d’autres. Les corpus de Wikipedia, disponible librement depuis les débuts de l’existence de l’encyclopédie sont eux aussi utilisés (ce qui explique la compréhension du Bengali par Google Bard et non la génération spontanée du langage – comme semblait le croire Sundar Pinchai …). Ces données ne sont pas les seules, de très nombreux corpus plus ou moins obscurs sont assurément ajoutés: on a démontré l’existence d’emails pour entraîner ChatGPT, probablement des ressources mathématiques, des QCM spécialisés. On sait qu’Axel Springer, mastodonte de la presse, a un accord de réutilisation de contenu (Politico et Business Insider) avec OpenAI.
L’exception au droit d’auteur pour les LLMs est elle une bonne idée ?
On l’a vu, il est possible de reproduire un texte original utilisé pour entraîner un LLM : nous l’avons montré dans ce post, des chercheurs l’ont démontré, la poursuite du New York Times contre Open AI le prouve à nouveau. Face à cette évidence, l’utilisation de données sous droits d’auteur, qu’elles soient obtenues par des moyens légaux (le crawl) ou illégaux (le corpus Books3) est elle acceptable et devrait elle faire l’objet d’une exception, comme le revendiquent avec tous les moyens de lobying dont ils disposent les mastodontes du web ?
OpenAI a ouvertement déclaré que la formation de modèles d’IA sans utiliser de matériel protégé par le droit d’auteur est « impossible », arguant que les juges et les tribunaux devraient rejeter les poursuites en indemnisation intentées par les titulaires de droits.
De son côté, Meta a reconnu avoir utilisé certaines parties de l’ensemble de données Books3, mais a fait valoir que son utilisation d’œuvres protégées par le droit d’auteur pour former des LLM ne nécessitait pas « de consentement, de crédit ou de compensation ». La société réfute les allégations de violation des droits d’auteur « présumés » des plaignants, affirmant que toute copie non autorisée d’œuvres protégées par le droit d’auteur dans Books3 devrait être considérée comme un usage loyal.
On imagine que tant Méta que OpenAI, s’ils voyaient les données de leurs applications commerciales (les fichiers publicitaires de Facebook par exemple ou le code source de ChatGPT pour OpenAI) tomber dans le domaine public suite à un hack (comme les auteurs des livres inclus dans Books3) seraient tout à fait d’accord pour qu’il soit réutilisé par des compétiteurs ? On connaît évidemment la réponse.
Cette histoire a un goût de déjà vu : à la fin des années 90, les fournisseurs d’accès Internet ont revendiqués le droit de ne pas être soumis à la loi pour les contenus qu’ils véhiculaient. Par extension, les médias sociaux (Facebook, Twitter, Youtube notamment) ont demandés eux aussi à bénéficier de ce statut, ce qu’ils ont obtenus. Dans la plupart des pays de l’OCDE, ils sont ainsi considérés comme des hébergeurs de contenu et à ce titre exonérés des contraintes qui pèsent sur la presse (notamment en matière de diffamation). Cette impunité leur a permis de littéralement siphoner les revenus de l’industrie des médias sans jamais se soumettre aux contraintes de qualité et de vérification des dits médias. La surabondance de la désinformation en ligne est l’une des conséquences de ce choix permissif fait par les législateurs il y a plus de vingt ans.
Après les lois sur la presse, c’est au droit des auteurs que les majors de la tech s’attaquent. N’hésitant pas à utiliser le fruit du hacking pour créer des produits commerciaux, en toute illégalité. Le travail d’un auteur de l’écrit, introduit dans un LLMs, produit pourtant de la valeur, et rien ne justifie que cette valeur soit captée sans contrepartie. Et il est certainement possible de faire prospérer cette technologie, sans pour autant demander à la société de détruire un édifice de protection des auteurs patiemment créer sur les trois derniers siècles. On ajoutera aussi que l’instabilité juridique qui se dessine autour des LLM et de leur données d’entraînement ne va pas faciliter leur adoption dans les grandes organisations dont les conseils ne manqueront pas de rappeler les risques légaux qu’ils posent.
Vous imaginez un chapitre d’un livre de Stephen King qui sortirait du bot d’un assureur ?