Cela fait plus de dix ans que l’intelligence artificielle est régulièrement présentée comme un agent de changement pour la pratique médicale. Mais les grands titres qu’on a pu voir sur de prétendues avancées, ont souvent débouchés sur des applications réelles controversées, voir dangereuses. Petit tour d’horizon factuel de la grandeur et de la décadence de quelques applications de l’IA en santé.
Cet article a été publié dans le dossier IA et Santé de la revue les Connecteurs dans le cadre de la collaboration des experts du Centre de Recherche Informatique de Montréal avec ce périodique.
https://lesconnecteurs.ca/lia-est-elle-bonne-pour-votre-sante/
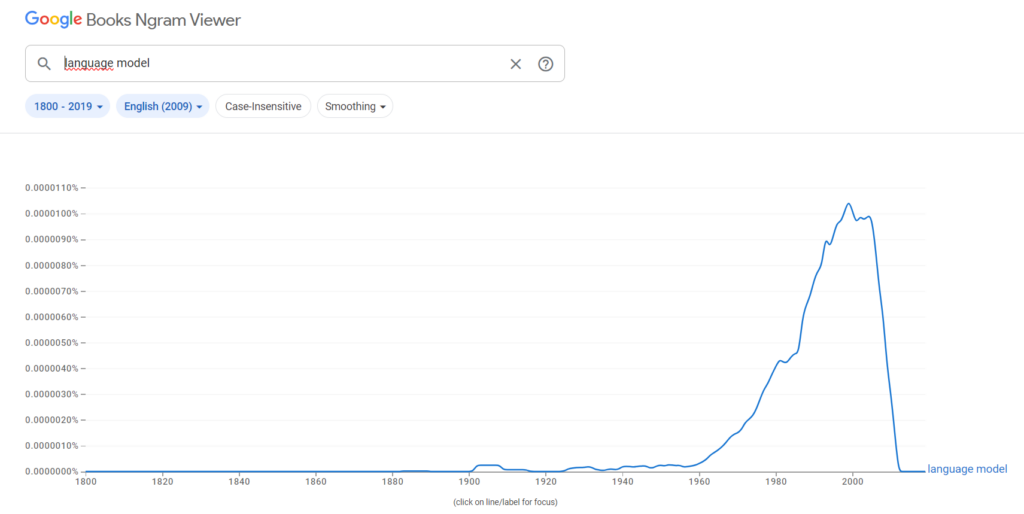
Notre récit commence en 20161, quand le désormais premier prix Nobel psychologue-Informaticien Geoffrey Hinton, pionnier de l’apprentissage profond, déclare que l’intelligence artificielle rendrait sous quelques années les médecins radiologues inutiles.
Des dizaines d’articles scientifiques se sont fait l’écho de cette extraordinaire nouvelle, au point d’inquiéter les radiologues et de donner des ailes à d’autres. Ainsi, en 2018, Christian Brunet, alors PDG du CHUM, annonce à l’occasion du lancement de son École de l’IA en santé2 que les radiologues devront repenser leur rôle, et parle d’optimiser les ressources en dermatologie grâce à l’IA.

Neuf ans plus tard, le monde connait une des plus grandes pénuries de radiologues de son histoire, bien que la plupart des fournisseurs de solutions radiologiques informatiques offrent des modules d’Intelligence Artificielle3.
Pourquoi une telle erreur dans la prédiction ? La fiction (ou la futurologie) s’est heurtée à la réalité. Algorithmes d’IA en radiologie il y a, sans aucun doute. Mais ils produisent tous sans exception un taux d’erreur plus ou moins important. Ils ne détectent jamais à 100% un cancer du sein ou une absence de cancer des poumons. Peut être dans 90% des cas, peut être 80%. Ils sont intelligents, mais ils se trompent.
Ce qui n’est pas un problème en soi : le taux d’erreur – les hallucinations de ChatGPT en sont une démonstration – est l’un des éléments constitutifs des modèles d’IA. Un système d’Intelligence artificielle se trompe comme un humain. Et quand Il doit mener un diagnostic dans un contexte difficile, avec une image d’un corps humain à chaque fois différent, qui implique un raisonnement poussé, ils se trompe plutôt plus qu’un humain.
Des mesures de mitigations doivent donc être mis en place. Dans le cas de la radiologie, la mitigation prend la forme d’une proposition par le système, que le professionnel de santé doit commenter à la lumière de sa propre expérience.
Ainsi, si votre médecin radiologue dans son compte rendu vous récite ce que l’IA a vu dans vos organes, sans le mettre en perspective, fuyez ! Si au contraire, il fait preuve de circonspection critique en indiquant que le module d’IA indique une pathologie x a tel
endroit, mais qu’après examen, il s’agit d’une erreur alors il fait un usage raisonné de la capacité supplémentaire que lui offre l’IA. Il s’en sert pour appuyer son diagnostic.
Vous l’avez compris, tant qu’un système d’Intelligence Artificielle de radiologie n’atteindra pas 100% de précision – ce qui n’est pas près d’arriver – le diagnostic humain sera incontournable. On continue donc de former des radiologues (et pas assez), malgré la prédiction de notre Nobel Canadien (qui n’est pas radiologue).
Watson et le cancer
Autre temps, autre intervenant, autre champs d’exercice de la médecine : milieu des années 2010, la société IBM annonce que son système d’Intelligence Artificielle Watson for Oncology (le même qui avait quelques mois plus tôt gagné le jeux télévisé Jéopardy) va révolutionner le traitement des patients cancéreux. Là encore, des dizaines de publications se font l’écho complaisant des communications d’IBM.
Quelques années plus tard, un article de la revue Stat révèle, en analysant des documents internes d’IBM, que Watson recommande des diagnostics dangereux et erronés de traitement du cancer4. En examinant l’utilisation de Watson for Oncology dans des hôpitaux en Corée du Sud, Slovaquie, États-Unis, les experts de Stats découvrent que IBM, pressé de positionner son système d’IA pour bénéficier de juteux contrats en santé, a lancé son produit en l’évaluant mal, et sans respecter les processus de revue par les pairs et d’expérimentation sur des patients humains.
Car habituellement, une méthode diagnostique et thérapeutique doit être testée avec de longues, coûteuses et fastidieuses études cliniques. Pas ici : Watson, système informatique qui n’entre pas dans les cases habituelles des agences de surveillances de la santé, va être directement appliqué à des cas cliniques. Ce sont les médecins et chercheurs de terrains qui vont alerter IBM sur ses lacunes ! Et quelles lacunes !
Au Texas, Le Centre de cancer Anderson de Houston collabore avec IBM pour développer son outil de décision clinique en oncologie. Cinq ans et 62 millions de dollars plus tard, le centre laisse expirer son contrat avec IBM5. Censé digérer les notes de médecins, les rapports et données sur les patients pour produire un diagnostic, Watson est incapable de produire un résultat exploitable.
A bien y regarder, le diagnostic médical par IA semble plus complexe que les questions du jeu télévisé Jeopardy.
Et IBM de découvrir (peut être un peu tard), que les institutions utilisent les termes médicaux de manières différentes. Et malgré les efforts des ingénieurs d’IBM, Watson ne parvient pas à interpréter le langage médical aussi bien que les humains. Ainsi, à l’hôpital M. D. Anderson, Watson n’a pas pu distinguer de manière fiable l’acronyme de la leucémie lymphoblastique aiguë, ALL, de l’abréviation d’allergie, qui est souvent également écrite ALL.
Selon l’audit de l’hopital, mené par le docteurs Andrew Norden et le vérifications conduites par le docteur Andrew Seidman, oncologue du Memorial Sloan Kettering Cancer Center de New York, les recommandations de traitement de Watson pendant le projet pilote sur le cancer du poumon étaient en accord avec celles de ses enseignants humains près de 90 % du temps. “C’est un niveau de précision très élevé”, reconnait Norden.
Mais une autre médecin, le docteur Abernethy complète le propos : “Que signifie réellement une précision de 90 % ?”. Et d’ajouter “cela signifie-t-il que pour des scénarios cliniques courants, la technologie s’est trompée 10 % du temps ? Ou cela signifie-t-il que 10 % du temps, Watson n’a pas pu aider dans les cas plus difficiles pour lesquels les décisions de traitement ne sont pas si évidentes ?”. Et que faire de ces 10% de diagnostics trompeurs qui conduisent des patients dans des scénarios thérapeutiques erronées pouvant conduire au décès ?
Question cruciale: jusqu’à quel point l’erreur (d’un taux plutôt élevé de surcroit) diagnostique d’un système d’Intelligence Artificielle est-elle acceptable ? Plus acceptable que celle d’un médecin ?
Demander un second, voire un troisième avis lors d’une maladie grave est une pratique courante du patient, comment s’exerce cette faculté avec un système informatique automatisé ?
ChatGPT entre dans la danse
On avait donc – lorsque ChatGPT entre dans la danse en 2022 – un historique tumultueux de la liaison dangereuse entre IA et diagnostic. Et qui pourtant n’allait pas arrêter nos apprentis sorciers (pardon médecins) de remettre le couvert. Imaginez ! Dans un contexte de pénurie de médecins et de coûts de santés de plus en plus difficiles à supporter, un agent conversationnel automatisé sur-intelligent qui après quelques questions peut vous orienter vers le bon traitement ou le bon médecin. Le remède miracle !
Sur le site d’OpenAI, encore aujourd’hui, un fournisseur d’agents (des entreprises qui utilisent les outils d’OpenAI pour créer leur propre service) affirme que ChatGpt peut servir d’assistant médical de diagnostic6. Mieux, un article du New York Times de novembre 2024 prétends en se basant sur une seule étude très préliminaire, que ChatGPT fait mieux que les médecins pour diagnostiquer les maladies ! Diantre, on nous referait donc le coup de la radiologie ?
Deux ans après, qu’en pensent les médecins ? A nouveau, après l’enthousiasme exagéré et les prétentions déraisonnable, quelques professionnels testent de façon rigoureuse l’agent et découvre qu’hallucinations ne riment pas avec soins de qualité. Le National Institute of Health nous affirme sans détour dans une étude que ChatGPT, dans sa forme actuelle, n’est pas précis en tant qu’outil de diagnostic. ChatGPT ne garantit pas nécessairement l’exactitude des informations, malgré la vaste quantité de données sur lesquelles il a été
formé. D’autres études toutes aussi sérieuses arriveront à la même conclusion : les large langage models n’améliorent pas le diagnostic et donc ne devraient pas être utilisé dans leur état actuel7 !
L’IA est-elle dangereuse pour la santé ?
A la lumière de ces exemples répétés de mauvais usages de l’IA dans le domaine du diagnostic médical, il ne fait guère de doute que les différentes applications de ces technologies dans le monde de la santé doivent être prises avec d’infinies précautions. Praticien de l’IA, je me souviens de la surprise de mon médecin de famille (j’ai la chance d’en avoir un), quand je lui ai indiqué que je refuserais d’être diagnostiqué par Watson (ou ses équivalents).
On rappellera que toutes les ‘expériences’ qui viennent d’être décrites ont un point commun : elles sont le produit d’entreprises commerciales qui ont un intérêt financier à aller vite et à s’affranchir des normes de santés contraignantes. Le milieu scientifique est lui contraint par des normes, fixées par des agences de santé et supervisées par des comités d’éthiques: on ne valide pas une méthode thérapeutique sans précautions.
Que conclure ? Que si l’interdisciplinarité est un bienfait (de facto, la création de nouveaux médicaments par les modèles d’IA génératifs est une prouesse très prometteuse), les informaticiens devraient se garder d’affirmer que des modèles d’IA vont révolutionner les soins de santé. Et de leur côté, les professionnels de santé devraient se garder d’utiliser l’IA sans s’être assuré préalablement que ce qui fait le succès de la médecine moderne – la vérification clinique de l’efficacité thérapeutique d’une méthode – a correctement été conduite pour les modèles d’Intelligence artificielle.